Wappkit Blog
How to Scrape Reddit Data in 2025: Python vs. No-Code Tools (Bypassing API Limits)
Stop wrestling with PRAW and API rate limits. Discover the easiest ways to scrape Reddit comments, posts, and media in 2025—from Python scripts to no-code desktop automation.
Article context
Read the guide inside the same Wappkit surface as the product.
Authors
Practical content, product pages, activation docs, and downloads should feel like one connected trust path instead of scattered templates.

Note: This article was migrated from the legacy site. Product packaging, free-vs-paid access, and pricing may have changed since publication. For the current Reddit Toolbox details, see /tools/reddit-toolbox.
If you've tried to scrape Reddit data recently, you probably ran into a wall.
In 2023, Reddit aggressively updated their API pricing and rate limits, effectively killing thousands of third-party apps (RIP Apollo). For data scientists, marketers, and developers, this meant one thing: Getting data from Reddit just got 10x harder.
Whether you are trying to analyze stock sentiment on r/wallstreetbets, train an AI model, or just backup your own profile, the old ways don't work like they used to.
In this guide, we'll cover the three main ways to scrape Reddit in 2025, ranked from "Hard Mode" to "God Mode."
Method 1: The "Official" Way (Python + PRAW)
If you are a developer, your first instinct is to use PRAW (Python Reddit API Wrapper). It's the industry standard library.
The Setup
You'll need to register an app on Reddit to get a client_id and client_secret.
import praw
reddit = praw.Reddit(
client_id="YOUR_CLIENT_ID",
client_secret="YOUR_CLIENT_SECRET",
user_agent="script:my_scraper:v1.0 (by u/username)"
)
# Scrape the top 10 posts from r/technology
for submission in reddit.subreddit("technology").hot(limit=10):
print(submission.title)❌ The Problem
While simple, this method has fatal flaws in 2025:
- Rate Limits: You are capped strictly. Try to scrape 10,000 comments, and your script will sleep for hours.
- Cost: If you need commercial-scale data, the API is incredibly expensive.
- Missing Data: You can't easily get historical data or NSFW content without extra hoops.
Method 2: The "Hacker" Way (Selenium / Puppeteer)
To bypass API limits, many turn to "Web Scraping" using headless browsers. This simulates a real user visiting the website.
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.reddit.com/r/technology")
# ... copious amounts of complex waiting and parsing logic ...❌ The Problem
- It's Slow: Rendering JavaScript for every page takes forever.
- Bot Detection: Reddit's WAF (Web Application Firewall) will block you with "403 Forbidden" or CAPTCHAs if you don't manage your browser fingerprints perfectly.
Method 3: The "Smart" Way (Reddit Toolbox)
This is why we built Reddit Toolbox.
We realized that most people don't want to write code—they just want the data.
Reddit Toolbox is a desktop application that combines the power of a headless browser with a user-friendly dashboard. It runs locally on your machine, using your own IP (or proxies), making it virtually unblockable.

✅ Why It's Better
- Unlimited Scraping: Since it mimics a real user, you aren't bound by API tiers.
- No Code Required: Just type a subreddit name and click "Start".
- Rich Media Support: Download videos (with sound!), images, and JSON data in one go.
How to Scrape r/wallstreetbets in 3 Clicks
- Open Reddit Toolbox.
- Enter
wallstreetbetsin the search bar. - Select your date range and click Export.
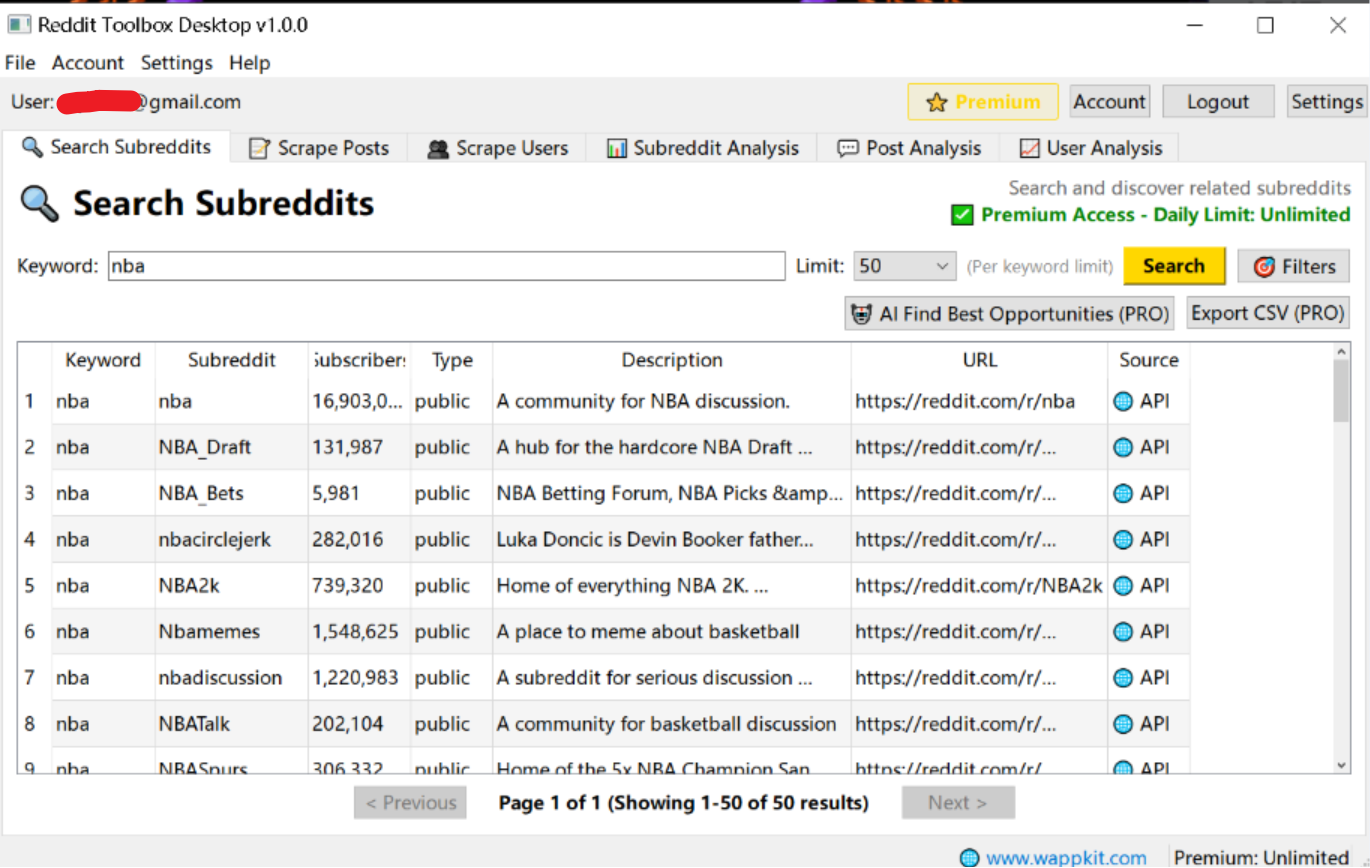
You'll get a clean CSV or JSON file ready for analysis in Excel, Tableau, or Python.
Conclusion
If you are building a production app, you might still need the official API. But for data analysis, marketing research, or archiving, manual coding is a waste of time.
Stop fighting the API. Start collecting data.
From Wappkit
Wappkit App Setup
Queue useful Windows apps faster, run setup packs, and unlock premium diagnostics and profile workflows with one license key.
Why it fits this blog
- - Starter packs and supported app install flow
- - Optional WinGet repair and diagnostics workflow
Wappkit App Setup is live with license activation flow and Creem checkout support.
From Wappkit
Wappkit App Setup
Queue useful Windows apps faster, run setup packs, and unlock premium diagnostics and profile workflows with one license key.
Why it fits this blog
- - Starter packs and supported app install flow
- - Optional WinGet repair and diagnostics workflow
Wappkit App Setup is live with license activation flow and Creem checkout support.